In our model:
- The spread \(d∼N(\mu,\tau)\) describes our best guess in the absence of polling data. We set \(\mu=0\) (don't know who's going to win) and \(\tau=0.035\) (using historical data).
The average of observed data \(\bar{X}∣d∼N(d,\sigma)\) describes randomness due to sampling and the pollster effect.
Because the posterior distribution is normal, we can report a 95% credible interval that has a 95% chance of overlapping the parameter using E(p∣Y) and SE(p∣Y) .
Given an estimate of E(p∣Y) and SE(p∣Y) , we can use pnorm to compute the probability that d>0 .
It is common to see a general bias that affects all pollsters in the same way. This bias cannot be predicted or measured before the election. We will include a term in later models to account for this variability.
Code: Definition of results object
library(dslabs)
polls <- polls_us_election_2016 %>%
filter(state == "U.S." & enddate >= "2016-10-31" &
(grade %in% c("A+", "A", "A-", "B+") | is.na(grade))) %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100)
one_poll_per_pollster <- polls %>% group_by(pollster) %>%
filter(enddate == max(enddate)) %>%
ungroup()
results <- one_poll_per_pollster %>%
summarize(avg = mean(spread), se = sd(spread)/sqrt(length(spread))) %>%
mutate(start = avg - 1.96*se, end = avg + 1.96*se)
Code: Computing credible interval and probability
tau <- 0.035
sigma <- results$se
Y <- results$avg
B <- sigma^2 / (sigma^2 + tau^2)
posterior_mean <- B*mu + (1-B)*Y
posterior_se <- sqrt(1 / (1/sigma^2 + 1/tau^2))
posterior_mean
posterior_se
# 95% credible interval
posterior_mean + c(-1.96, 1.96)*posterior_se
# probability of d > 0
1 - pnorm(0, posterior_mean, posterior_se)
[1] 1
Mathematical Representations of Models
If we collect several polls with measured spreads \((X_1,...,X_j)\) with a sample size of N , these random variables have expected value \(d\) and standard error \(2\sqrt{p(1−p)/N}\).
For one polster we represent each measurement as \[X_j=d+\epsilon_j\] where
- j - index for diffferent polls
- d - actual spread of the election
- \(\epsilon\) - error assocaited with poll
Code: Simulated data for one pollster
N <- 2000
d <- .021
p <- (d+1)/2
X <- d + rnorm(J, 0, 2*sqrt(p*(1-p)/N))
Using data for several pollsters brings house effect (h) \[X_{ij}=d+h_i+\epsilon_{ij}\] where
- i - index for diffferent pollster
- h - house effect for each pollster
Code: Simulated data for several pollsters
J <- 6
N <- 2000
d <- .021
p <- (d+1)/2
h <- rnorm(I, 0, 0.025) # assume standard error of pollster-to-pollster variability is 0.025
X <- sapply(1:I, function(i){
d + rnorm(J, 0, 2*sqrt(p*(1-p)/N))
})
In addition, there is a general bias affecting all pollsters (b) \[X_{ij}=d+b+h_i+\epsilon_{ij}\]
The sample average is now is \[\bar{X}=d+b+\frac{\sum_{i=1}^{N}X_i}{N}\]
Standard deviation is \[SE(\bar{X})=\sqrt{\sigma^2/N+\sigma_b^2}\]
The standard error of the general bias \(\sigma_b\) does not get reduced by averaging multiple polls, which increases the variability of our final estimate. If we redo the Bayesian calculation taking this variability into account, we get a result much closer to FiveThirtyEight’s:
Code: Computing credible interval and probability
tau <- 0.035
sigma <- sqrt(results$se^2 + .025^2) #$
Y <- results$avg #$
B <- sigma^2 / (sigma^2 + tau^2)
posterior_mean <- B*mu + (1-B)*Y
posterior_se <- sqrt( 1/ (1/sigma^2 + 1/tau^2))
1 - pnorm(0, posterior_mean, posterior_se)
[1] 0.817
Predicting the Electoral College
In the US election, each state has a certain number of votes that are won all-or-nothing based on the popular vote result in that state (with minor exceptions not discussed here).
We use the left_join() function to combine the number of electoral votes with our poll results. For each state, we apply a Bayesian approach to generate an Election Day d . We keep our prior simple by assuming an expected value of 0 and a standard deviation based on recent history of 0.02.
Code: Top 5 states ranked by electoral votes
library(dslabs)
data("polls_us_election_2016")
head(results_us_election_2016)
results_us_election_2016 %>% arrange(desc(electoral_votes)) %>% top_n(5, electoral_votes)
- > state electoral_votes clinton trump others
- > 1 California 55 61.7 31.6 6.7
- > 2 Texas 38 43.2 52.2 4.5
- > 3 Florida 29 47.8 49.0 3.2
- > 4 New York 29 59.0 36.5 4.5
- > 5 Illinois 20 55.8 38.8 5.4
- > 6 Pennsylvania 20 47.9 48.6 3.6
We use the left_join() function to combine the number of electoral votes with our poll results.
For each state, we apply a Bayesian approach to generate an Election Day d . We keep our prior simple by assuming an expected value of 0 and a standard deviation based on recent history of 0.02.
Code: Computing the average and standard deviation for each state
filter(state != "U.S." &
!grepl("CD", "state") &
enddate >= "2016-10-31" &
(grade %in% c("A+", "A", "A-", "B+") | is.na(grade))) %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100) %>%
group_by(state) %>%
summarize(avg = mean(spread), sd = sd(spread), n = n()) %>%
mutate(state = as.character(state))
# 10 closest races = battleground states
results %>% arrange(abs(avg))
# joining electoral college votes and results
results <- left_join(results, results_us_election_2016, by="state")
# states with no polls: note Rhode Island and District of Columbia = Democrat
results_us_election_2016 %>% filter(!state %in% results$state)
# assigns sd to states with just one poll as median of other sd values
results <- results %>%
mutate(sd = ifelse(is.na(sd), median(results$sd, na.rm = TRUE), sd))
Code: Calculating the posterior mean and posterior standard error
tau <- 0.02
results %>% mutate(sigma = sd/sqrt(n),
B = sigma^2/ (sigma^2 + tau^2),
posterior_mean = B*mu + (1-B)*avg,
posterior_se = sqrt( 1 / (1/sigma^2 + 1/tau^2))) %>%
arrange(abs(posterior_mean))
We can run a Monte Carlo simulation that for each iteration simulates poll results in each state using that state's average and standard deviation, awards electoral votes for each state to Clinton if the spread is greater than 0, then compares the number of electoral votes won to the number of votes required to win the election (over 269).
Code: Monte Carlo simulation of Election Night results
tau <- 0.02
clinton_EV <- replicate(1000, {
results %>% mutate(sigma = sd/sqrt(n),
B = sigma^2/ (sigma^2 + tau^2),
posterior_mean = B*mu + (1-B)*avg,
posterior_se = sqrt( 1 / (1/sigma^2 + 1/tau^2)),
simulated_result = rnorm(length(posterior_mean), posterior_mean, posterior_se),
clinton = ifelse(simulated_result > 0, electoral_votes, 0)) %>% # award votes if Clinton wins state
summarize(clinton = sum(clinton)) %>% # total votes for Clinton
.$clinton + 7 # 7 votes for Rhode Island and DC
})
mean(clinton_EV > 269) # over 269 votes wins election
# histogram of outcomes
data.frame(clintonEV) %>%
ggplot(aes(clintonEV)) +
geom_histogram(binwidth = 1) +
geom_vline(xintercept = 269)
[1] 0.998
If we include a general bias term, the estimated probability of Clinton winning decreases significantly.
Code: Monte Carlo simulation including general bias
tau <- 0.02
bias_sd <- 0.03
clinton_EV_2 <- replicate(1000, {
results %>% mutate(sigma = sqrt(sd^2/(n) + bias_sd^2), # added bias_sd term
B = sigma^2/ (sigma^2 + tau^2),
posterior_mean = B*mu + (1-B)*avg,
posterior_se = sqrt( 1 / (1/sigma^2 + 1/tau^2)),
simulated_result = rnorm(length(posterior_mean), posterior_mean, posterior_se),
clinton = ifelse(simulated_result > 0, electoral_votes, 0)) %>% # award votes if Clinton wins state
summarize(clinton = sum(clinton)) %>% # total votes for Clinton
.$clinton + 7 # 7 votes for Rhode Island and DC
})
mean(clinton_EV_2 > 269) # over 269 votes wins election
[1] 0.848
Forecasting
In poll results, p is not fixed over time. Variability within a single pollster comes from time variation.
Code: Variability across one pollster
one_pollster <- polls_us_election_2016 %>%
filter(pollster == "Ipsos" & state == "U.S.") %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100)
# the observed standard error is higher than theory predicts
se <- one_pollster %>%
summarize(empirical = sd(spread),
theoretical = 2*sqrt(mean(spread)*(1-mean(spread))/min(samplesize)))
se
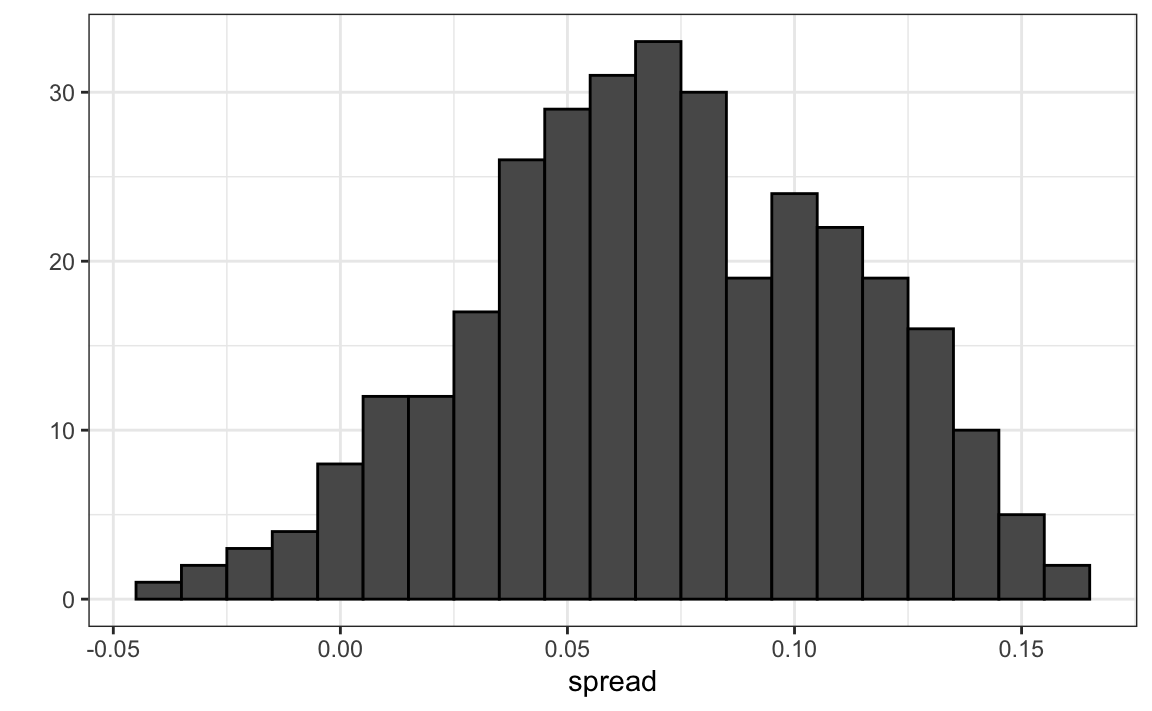
- > empirical theoretical
- > 1 0.0403 0.0326
one_pollster %>% ggplot(aes(spread)) +
geom_histogram(binwidth = 0.01, color = "black")
In order to forecast, our model must include a bias term \(b_t\) to model the time effect. Pollsters also try to estimate f(t) , the trend of p given time t using a model like: \[Y_{ij}=d+b+h_j+b_t+\epsilon_{ij}\]
Code: Trend across time for several pollsters
filter(state == "U.S." & enddate >= "2016-07-01") %>%
group_by(pollster) %>%
filter(n() >= 10) %>%
ungroup() %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100) %>%
ggplot(aes(enddate, spread)) +
geom_smooth(method = "loess", span = 0.1) +
geom_point(aes(color = pollster), show.legend = FALSE, alpha = 0.6)
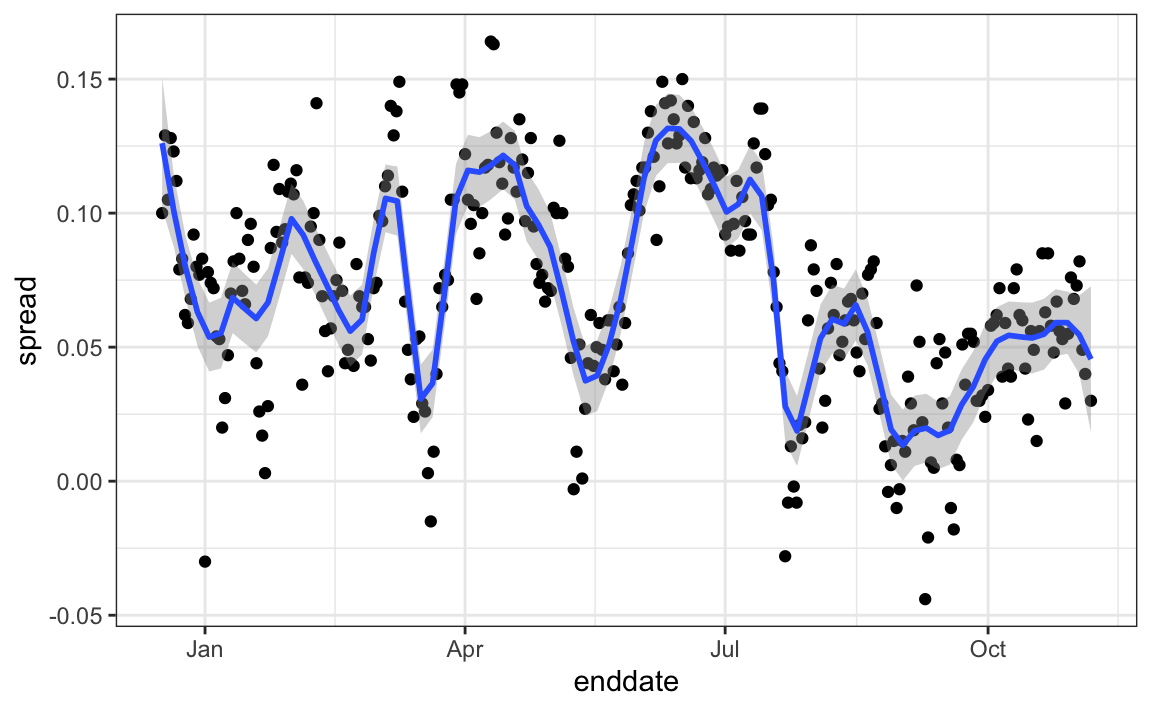
Once we decide on a model, we can use historical data and current data to estimate the necessary parameters to make predictions.
Election Forecasting - Exercises
The t-Distribution
In models where we must estimate two parameters, p and σ, the Central Limit Theorem can result in overconfident confidence intervals for sample sizes smaller than approximately 30.
If the population data are known to follow a normal distribution, theory tells us how much larger to make confidence intervals to account for estimation of σ.
Given s as an estimate of σ , then \[Z=\frac{\bar{X}-d}{s\sqrt{N}} follows a t-distribution with N−1 degrees of freedom.
Degrees of freedom determine the weight of the tails of the distribution. Small values of degrees of freedom lead to increased probabilities of extreme values.
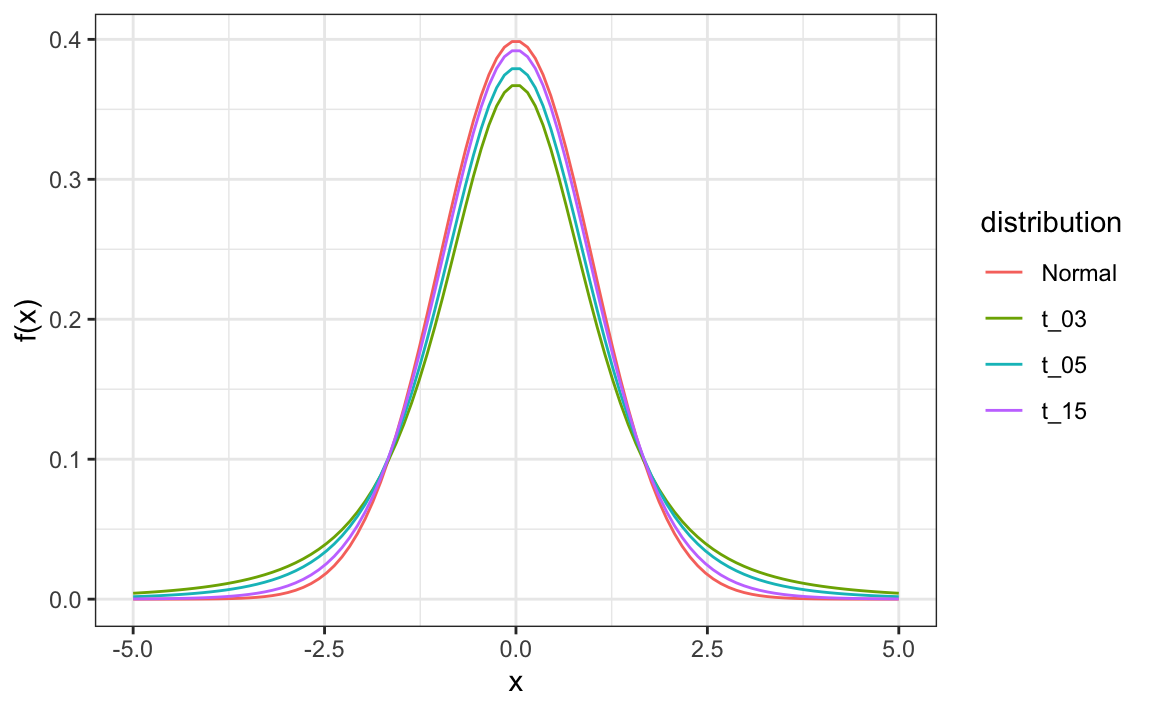
We can determine confidence intervals using the t-distribution instead of the normal distribution by calculating the desired quantile with the function qt().
Code: Calculating 95% confidence intervals with the t-distribution
one_poll_per_pollster %>%
summarize(avg = mean(spread), moe = z*sd(spread)/sqrt(length(spread))) %>%
mutate(start = avg - moe, end = avg + moe)
# quantile from t-distribution versus normal distribution
qt(0.975, 14) # 14 = nrow(one_poll_per_pollster) - 1
[1] 2.14
[1] 1.96